学习Python从base64格式的HTML中提取图片
Onew前言
今天准备把前几年在手机上写的小作文转到博客上,但是发现导出的格式是base64的HTML文件(尝试导出过word或者pdf格式,但是不尽人意),其中的图片就不是那么方便复制,而且是原图,占用的空间比较大。于是就有了下面这段Python代码。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
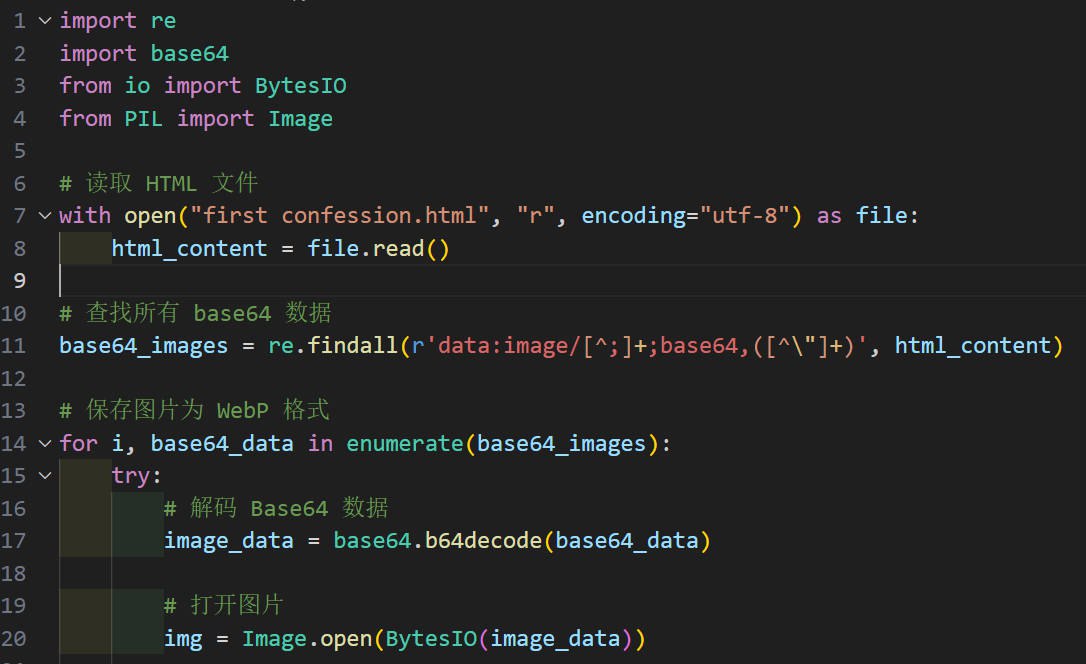
| import re
import base64
from io import BytesIO
from PIL import Image
with open("your_file.html", "r", encoding="utf-8") as file:
html_content = file.read()
base64_images = re.findall(r'data:image/[^;]+;base64,([^\"]+)', html_content)
for i, base64_data in enumerate(base64_images):
try:
image_data = base64.b64decode(base64_data)
img = Image.open(BytesIO(image_data))
img = img.convert("RGB")
file_name = f"image_{i + 1}.webp"
img.save(file_name, "WEBP", quality=80)
print(f"图片已保存为 {file_name}")
except Exception as e:
print(f"转换失败:{e}")
|
效果演示